Testing Large Context LLMs

I had taken a break from following open-source large language models for a few months, but with some new models appearing on the leaderboards and larger context-length appearing, here are some of the few notable ones I’m trying out.
Context on context length
If you are new to large language models, context length refers to the amount of text that can be stored in a large language model chat. When Llama was first released the context length was a limitation. Most models were only 2-4K, while OpenAI was well ahead. As of this writing OpenAI now offers a 128K version while open-source is offering options from 128K-200K, so over this year you can see open-source passing OpenAI. It’s worth noting that Anthropic has offered a 100K context length LLM as one of their key differentiators for some time.
In open-source there have been iterations up to 8K and 16K models, namely StarCoder/WizardCoder and also some suspicious that larger than recommended context works. I recently found some other evidence of this from Green-Sky referencing the YaRN paper, suggesting that for coding models like Code Llama setting the context larger is acceptable.
Models
Yi-6B/33B
This is the new top of the leaderboard and also boasts a 200K context window. This is the first I’ve heard of o1.ai which is aims to be the OpenAI of China. Their license is not fully commercial, so research purposes only unless they approve.
Yarn Mistral-7B
Yarn refers to the context limit extension technique, mistral.ai has emerged as a LLM startup able to create very capable small models. They also offer a 128K context model that I’m testing.
Phind CodeLlama 34B
Phind has created a really useful chat for coding, and has recently extended to offering fine tuned versions of CodeLlama, the version of Llama optimized for coding tasks. Here is a link to the model.
Results
Since this is all new I want to give this a heavily disclaimer that things will change. To test this I simply changed the `-c` option when running the llama.cpp server locally.
200K context with the Yi-6B was possible, but only ~83K with the 33B model. I was able to get over 125K with the Yi-6B on a 32GB M1 Pro, but less impressive results with the Mistral-7B. Again there could be a lot of reasons for variation here beyond the models. I think most people would be satisfied with over 64K at this point, and I would expect improvements to continue to make this obsolete.
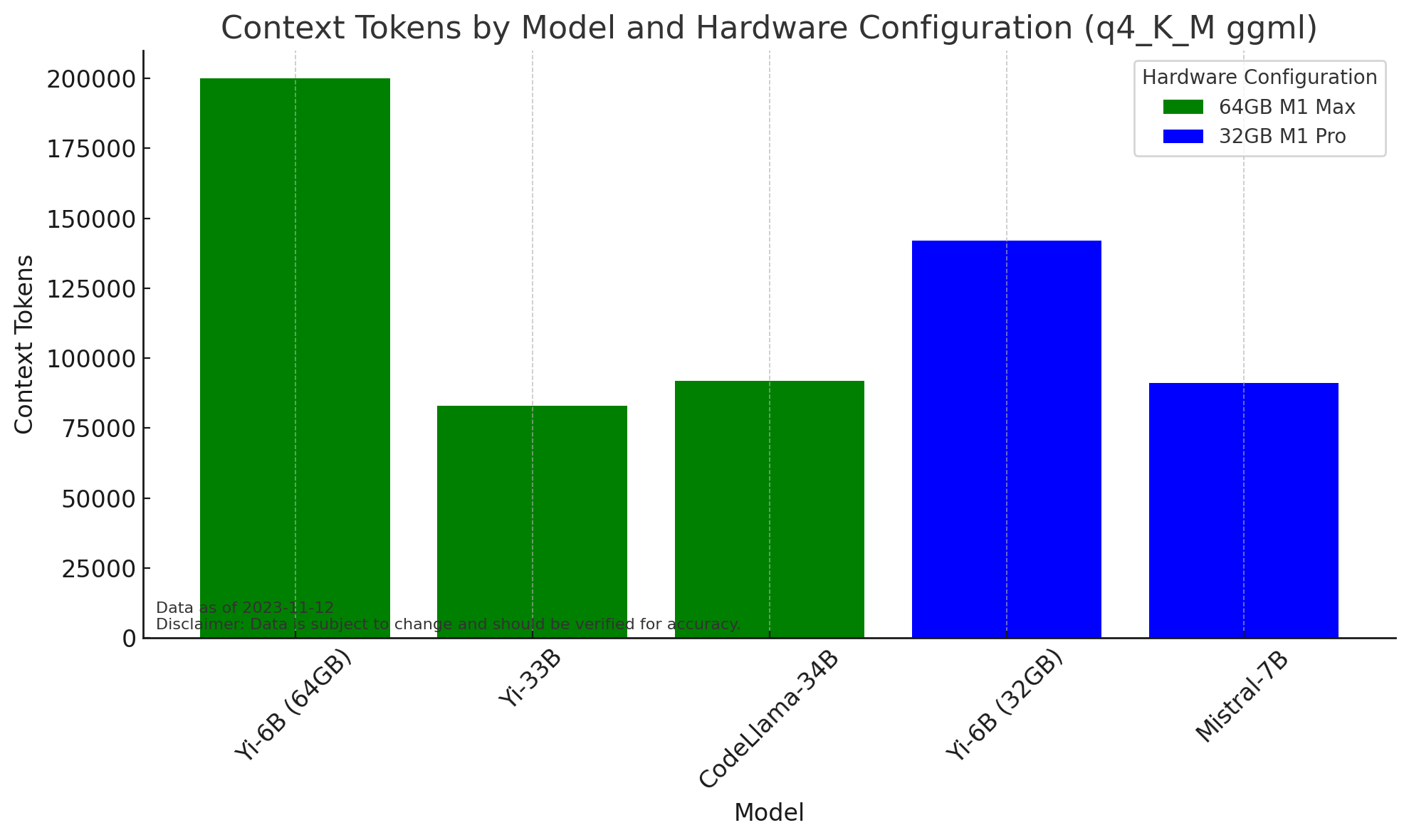
Getting over 90K with CodeLlama was the biggest surprise, I’m going to find ways to test this out to see if it can work better than GPT-4 for coding with large files.
Given the resource constraints of increased context length the benefit of running a local LLM vs GPT-4 shifts. While I expect ChatGPT to be more reliable over time I believe it will be fundamentally be more efficient to run LLMs on-device if larger context options are available from open-source.